Des robots pour visiteurs
Quand je lis les journaux de mon serveur Web, j'ai l'impression que la plupart des visiteurs sont des robots.
La part des visiteurs qui s'identifient comme des robots via leur user agent est passée de moins de 30 % début 2024 à 40 % en décembre.
L'entraînement des modèles d'IA générative tels que les LLM nécessite un corpus toujours plus grand de données. Les entreprises du secteur ont donc développé des programmes qui parcourent le Web pour enregistrer le contenu des sites visités. Aux visiteurs de longue date que sont Googlebot et Bingbot se sont ajoutés GPTBot, ClaudeBot, Amazonbot, et bien d'autres.
Comment évaluer la part des robots parmi les visiteurs à partir des journaux ?
Les serveurs Web comme Apache enregistrent des informations sur les requêtes HTTP traitées dans un fichier journal des accès. Parmi ces informations figure l'en-tête user agent de la requête HTTP. Il s'agit d'une chaîne de caractère qui identifie le navigateur Web.
Le user agent des robots d'indexation contient en général les termes bot, crawler ou spider. Toutefois, un robot peut prétendre être un banal navigateur Web en usurpant son user agent.
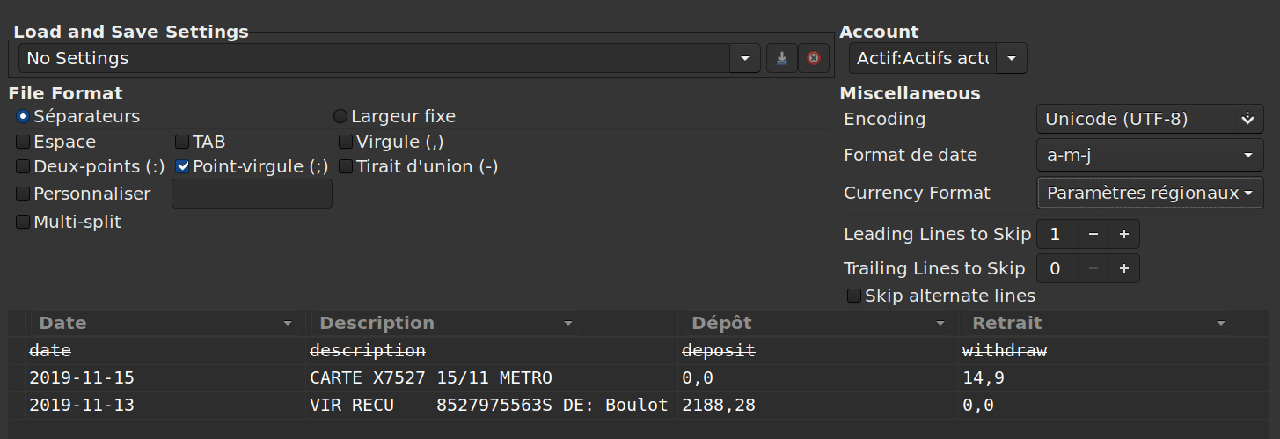
Je suggère d'utiliser le logiciel libre Angle-grinder pour analyser le fichier journal des accès d'Apache et estimer le ratio des requêtes valides envoyées par des robots.
$ agrind -f a.log "* | apache | where status == 200 | if(contains(toLowerCase(contentlength), 'bot'), 1, 0) as bot_req | avg(bot_req) as bot_req_ratio" bot_req_ratio --------------------- 0.40
Les pipelines, séparés par le caractère |, sont composés ainsi :
- Toutes les entrées du fichier journal sont sélectionnées avec le
caractère
*. - Le parser pour le format du journal d'Apache interprète les champs.
- Seules les requêtes dont le statut de réponse HTTP est 200 sont conservées. En effet, de nombreuses requêtes sont invalides et ne nous intéressent pas. Par exemple, des requêtes émanant de robots à la recherche de vulnérabilités à exploiter.
- De façon étrange, le user agent est contenu dans le champ
contentlength. Si le champ contient la chaîne de caractères"bot", on définit le champbot_reqà 1, sinon à 0. On peut étendre cette condition pour inclure les termes moins fréquents"crawler"et"spider". - Enfin, la valeur moyenne du champ
bot_reqest calculée.
Quels sont les robots les plus actifs ?
Voici la liste des cinq robots les plus actifs sur ce site en 2024.
| Rang | Nom du robot | Propriétaire | Part des requêtes HTTP |
|---|---|---|---|
| 1 | Googlebot | 4.72 % | |
| 2 | GPTBot | OpenAI | 2.82 % |
| 3 | bingbot | Microsoft | 1.50 % |
| 4 | YandexBot | Yandex | 1.34 % |
| 5 | Bytespider | ByteDance | 1.01 % |
Comment a évolué l'activité des robots au cours de l'année ?
Les graphiques qui suivent représentent l'activité des robots les plus connus sous la forme d'une carte thermique du calendrier.
Chaque case symbolise un jour de l'année. Les jours se suivent verticalement du lundi au dimanche et sont groupés par mois. La couleur d'une case varie du jaune pâle au rouge foncé en fonction du nombre de requêtes HTTP reçues ce jour là.
Les graphiques sont affichés par la bibliothèque JavaScript Cal-Heatmap.
Googlebot
Très actifs, les robots de Google ont visité le site tous les jours en 2024.
GPTBot
Les robots d'OpenAI ont visité le site 212 jours en 2024. Rares en début d'année, ils ont été très présents en octobre.
Bingbot
Les robots de Microsoft ont visité le site tous les jours en 2024.
YandexBot
Les robots de Yandex ont visité le site 342 jours en 2024 mais ont été plus discrets à partir du mois de septembre.
Bytespider
Les robots de ByteDance ont visité le site 254 jours en 2024 et ont été plus actifs de juillet à septembre.
AmazonBot
Les robots d'Amazon apparaissent au septième rang et se distinguent dans leurs accès : ils indexent l'ensemble du site une fois par mois.
ClaudeBot
Classés au neuvième rang par leur activité, les robots d'Anthropic ont visité le site 50 jours en 2024, principalement en avril et en mai.
IA quelqu'un ?
Les robots représentent une part croissante des visiteurs de ce site. Ils deviendront peut-être majoritaires en 2025.
Toutefois, j'aimerais qu'ils butinent plus sobrement le contenu du site pour ne pas consommer inutilement ses ressources informatiques.
Ils pourraient s'inspirer de l'efficacité discrète de ce butineur insaisissable.

Un Moro-sphinx (Macroglossum stellatarum) butine du Chèvrefeuille.